DEEP LEARNING
Sigmoid系活性化関数
ニューラルネットワークの古典的な活性化関数です。入力を0〜1(Sigmoid)や-1〜1(tanh)の範囲に滑らかに押し込めます。ReLU系が登場する前はこれらが主流でした。
解説
🧠Sigmoid系関数とは
Sigmoid系関数は、どんな大きさの入力でも、決まった範囲(0〜1 や -1〜1)に滑らかに押し込める関数です。 蛇口のハンドルに例えると、ハンドルをどれだけ大きく回しても水の量には上限がある — そんなイメージです。1980〜2000年代のニューラルネットワークではSigmoidとtanhが標準でした。 現在はロジスティック回帰の出力層(確率を表すため0〜1が必要)やRNNのゲート機構(LSTMの忘却ゲートなど)で活躍しています。 隠れ層にはReLU系が主流になりましたが、Sigmoid系を理解することはディープラーニングの基礎として重要です。
⚡Sigmoid系関数の特徴
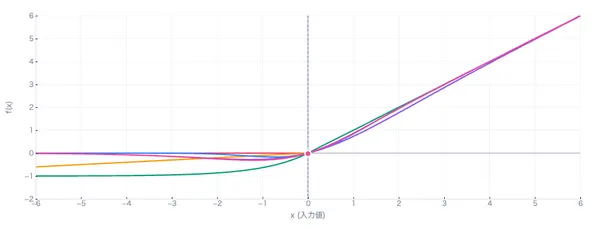
- 📏出力の範囲が限定される:Sigmoidは0〜1、tanhは-1〜1に出力を閉じ込めます。「確率」として解釈したいときにSigmoidが便利です(0.8なら80%の確率)。上のグラフでx=±8でも出力が1や-1を超えないことを確認してください。
- 📉勾配消失問題:Sigmoidの導関数の最大値はわずか0.25です。逆伝播で層ごとに掛け算されるため、10層あると 0.25¹⁰ ≈ 0.00000095 — 勾配がほぼ消えます。これが深いネットワークでSigmoidが使われなくなった最大の理由です。導関数グラフの青い山がどれほど低いか見てみてください。
- ⚖️ゼロ中心性:Sigmoidは出力が常に正(0〜1)なので、次の層への入力が偏ります。tanhは-1〜1でゼロ中心のため、Sigmoidよりも学習が効率的です。実際にLSTMの内部ではSigmoidとtanhが役割を分けて使われています。
- ⚙️計算コスト:Sigmoidとtanhはeˣやlnといった指数・対数計算が必要です。Hard Sigmoidは単純な四則演算(0.2x + 0.5のクリッピング)だけで近似でき、モバイル向けモデル(MobileNetなど)で使われています。
🎯現在のユースケース
📊 ロジスティック回帰の出力層
二値分類で「この入力がクラスAに属する確率」を0〜1で出すためにSigmoidを使います。スパムメール判定、病気の診断など
🧩 LSTMのゲート機構
LSTMの忘却ゲート・入力ゲート・出力ゲートはSigmoidで0〜1の値を作り、情報を「どれだけ通すか」を制御します
📱 モバイル向けモデル
Hard Sigmoidは計算が軽いため、MobileNetやスマートフォン上のAIモデルでSigmoidの代用として使われます
🔤 RNN/LSTMの隠れ層
RNN系のモデルでは隠れ層にtanhが標準的に使われます。出力が-1〜1でゼロ中心のため、時間方向の勾配が安定します
📖用語解説
飽和(Saturation)
= 入力を大きくしても出力が変わらなくなる現象
= 入力を大きくしても出力が変わらなくなる現象
Sigmoidは x>5 あたりで出力がほぼ1に張り付き、x<-5 でほぼ0に張り付きます。 この「張り付いた」状態を飽和と呼びます。飽和した領域では導関数がほぼ0なので学習が進みません。 上のツールで x を±6以上に動かすと、値がほぼ変わらないことが確認できます。
ゲイン k(Gain)
= Sigmoidカーブの急峻さを制御するパラメータ
= Sigmoidカーブの急峻さを制御するパラメータ
σ(kx) の k です。k=1 が標準のSigmoidで、k を大きくするとカーブが急になり、ステップ関数(0か1かの二値)に近づきます。 k を小さくすると緩やかになり、直線 y=0.5 に近づきます。 上のツールで「Sigmoid ゲイン k」スライダーを動かして変化を見てみてください。
ゼロ中心(Zero-centered)
= 出力の平均が0に近い性質
= 出力の平均が0に近い性質
Sigmoidの出力は常に正(0〜1)です。次の層のニューロンから見ると入力が常に正なので、重みの更新方向が制限され学習が非効率になります。 tanhは出力が-1〜1でゼロ中心のため、この問題がありません。これがtanhがSigmoidより好まれる理由の一つです。
勾配消失問題(Vanishing Gradient Problem)
= 深い層で勾配が消える問題
= 深い層で勾配が消える問題
逆伝播では各層の導関数を掛け合わせて勾配を計算します。Sigmoidの導関数の最大値は0.25なので、5層で 0.25⁵ ≈ 0.001、10層で約0.000001にまで縮みます。 これが「勾配消失」で、入力に近い層ほど学習が全く進まなくなります。ReLU系はこの問題を解決するために生まれました。
1Sigmoid(シグモイド関数)
S字カーブの代名詞で、出力を0〜1の確率として解釈できることが最大の特徴です。 ロジスティック回帰の出力層やLSTMのゲート機構で現在も不可欠な関数です。
計算式
σ(x) = 1 / (1 + e⁻ˣ)
e⁻ˣ はネイピア数 e(≈2.718)の -x 乗です。 x が大きいと e⁻ˣ → 0 なので σ(x) → 1/(1+0) = 1。 x が大きく負だと e⁻ˣ → ∞ なので σ(x) → 1/∞ = 0。 x=0 のとき e⁰ = 1 なので σ(0) = 1/(1+1) = 0.5(ちょうど真ん中)。
導関数(勾配)
σ'(x) = σ(x) · (1 - σ(x))
Sigmoidの導関数は「自分自身の値を使って計算できる」という美しい性質を持ちます。 σ(x) が 0 か 1 に近いとき、(1-σ(x)) か σ(x) が 0 に近くなるため、積はほぼ 0 です。 最大値は x=0 のとき 0.5 × 0.5 = 0.25。 ReLUの導関数が1なのと比べると、4分の1しかありません。
具体的な計算例
σ(0) = 1/(1+e⁰) = 1/(1+1) = 0.500
σ(2) = 1/(1+e⁻²) = 1/(1+0.135) ≈ 0.881
σ(-2) = 1/(1+e²) = 1/(1+7.389) ≈ 0.119
σ(5) = 1/(1+e⁻⁵) = 1/(1+0.007) ≈ 0.993(ほぼ1)
σ(2) = 1/(1+e⁻²) = 1/(1+0.135) ≈ 0.881
σ(-2) = 1/(1+e²) = 1/(1+7.389) ≈ 0.119
σ(5) = 1/(1+e⁻⁵) = 1/(1+0.007) ≈ 0.993(ほぼ1)
σ(x) + σ(-x) = 1 という対称性があります。σ(2) ≈ 0.881 なら σ(-2) ≈ 0.119 で、合計1です。
2tanh(ハイパボリックタンジェント)
Sigmoidをゼロ中心に移動してスケールした関数です。 数学的には tanh(x) = 2σ(2x) - 1 という関係があり、Sigmoidの親戚です。 RNN(特にLSTM・GRU)の隠れ層で標準的に使われています。
計算式
tanh(x) = (eˣ - e⁻ˣ) / (eˣ + e⁻ˣ)
分子は eˣ と e⁻ˣ の差、分母は和です。 x が大きいとき eˣ が支配的で、(eˣ - 0)/(eˣ + 0) → 1。 x が大きく負のとき e⁻ˣ が支配的で、(0 - e⁻ˣ)/(0 + e⁻ˣ) → -1。 x=0 のとき (1-1)/(1+1) = 0。Sigmoidとの関係:
tanh(x) = 2σ(2x) - 1
Sigmoidの出力を2倍して1を引くと tanh になります。形は同じS字で、出力範囲が -1〜1 に広がったものです。
導関数(勾配)
tanh'(x) = 1 - tanh²(x)
Sigmoidと同様に「自分自身の値から計算できる」性質を持ちます。 x=0 で最大値 1 - 0² = 1 を取ります。Sigmoidの最大値0.25と比べて4倍大きいため、勾配消失が緩和されます。 ただし |x| > 2 あたりで急速に0に近づくので、深い層では依然として問題になります。
具体的な計算例
tanh(0) = (1-1)/(1+1) = 0.000
tanh(1) = (2.718-0.368)/(2.718+0.368) ≈ 0.762
tanh(-1) = -0.762(原点対称)
tanh(3) ≈ 0.995(ほぼ1に飽和)
tanh(1) = (2.718-0.368)/(2.718+0.368) ≈ 0.762
tanh(-1) = -0.762(原点対称)
tanh(3) ≈ 0.995(ほぼ1に飽和)
tanh は原点対称(奇関数)で、tanh(-x) = -tanh(x) です。上のグラフで緑の線が原点を通り対称的なS字を描くことを確認してください。
3Hard Sigmoid
Sigmoidの区分線形近似です。指数関数(eˣ)を使わず、足し算・掛け算・クリッピングだけで計算できるため、計算が非常に高速です。スマートフォンやIoTデバイスなど、計算資源が限られた環境で活躍します。
計算式
f(x) = clamp(0.2x + 0.5, 0, 1)
clamp は「範囲を制限する」関数で、0未満なら0に、1より大きければ1に切り詰めます。 つまり:
x ≤ -2.5 のとき → f(x) = 0
-2.5 < x < 2.5 のとき → f(x) = 0.2x + 0.5
x ≥ 2.5 のとき → f(x) = 1
3つの直線をつなぎ合わせた形です。上のグラフで黄色の線を見ると、Sigmoid(青)と似た形をしていますが角があることがわかります。
導関数(勾配)
f'(x) = 0.2 (-2.5 < x < 2.5)
f'(x) = 0 (それ以外)
f'(x) = 0 (それ以外)
導関数は 0 か 0.2 の2値しか取りません。|x| < 2.5 の範囲でのみ勾配が0.2で、この範囲外では勾配が0です。 Sigmoidの導関数(滑らかな山型)と比べると非常にシンプルです。
具体的な計算例
f(0) = clamp(0+0.5, 0, 1) = 0.500
f(2) = clamp(0.4+0.5, 0, 1) = 0.900
f(-2) = clamp(-0.4+0.5, 0, 1) = 0.100
f(3) = clamp(0.6+0.5, 0, 1) = clamp(1.1, 0, 1) = 1.000
f(-5) = clamp(-1.0+0.5, 0, 1) = clamp(-0.5, 0, 1) = 0.000
f(2) = clamp(0.4+0.5, 0, 1) = 0.900
f(-2) = clamp(-0.4+0.5, 0, 1) = 0.100
f(3) = clamp(0.6+0.5, 0, 1) = clamp(1.1, 0, 1) = 1.000
f(-5) = clamp(-1.0+0.5, 0, 1) = clamp(-0.5, 0, 1) = 0.000
指数関数を一切使わないので、CPUでもGPUでも高速に計算できます。MobileNetV3ではHard SwishというHard Sigmoidの派生が使われています。
🔗Sigmoidとtanhの数学的な関係
SigmoidとtanhはS字カーブという同じ形状を持ち、数学的にも密接に関係しています。
変換公式
tanh(x) = 2σ(2x) - 1
σ(x) = (tanh(x/2) + 1) / 2
σ(x) = (tanh(x/2) + 1) / 2
tanhはSigmoidを縦方向に2倍に伸ばして、下に1ずらしたものです。 Sigmoidが [0, 1] に収める関数なら、tanhは同じ形を [-1, 1] に収めます。
LSTMでの使い分け
LSTMでは両方の関数が使われますが、役割が異なります:
Sigmoid → ゲート(門番)
0〜1の値で「どれだけ情報を通すか」を決める。0なら完全に遮断、1なら全て通す。忘却ゲート・入力ゲート・出力ゲートに使用
tanh → 値の変換
-1〜1の値で「新しい記憶の候補」を作る。ゼロ中心なのでセル状態の更新が安定する。候補生成・出力変換に使用