CLASSIFICATION VISUALIZER
ロジスティック回帰
合格か不合格か――2択の問題を確率で予測する、分類の基本アルゴリズム
解説
📌ロジスティック回帰とは
ロジスティック回帰は、「合格か不合格か」「クリックするかしないか」のような2択の結果を予測するアルゴリズムです。 最終的な答えは「合格」か「不合格」の分類ですが、その判定のために内部でまず確率を計算するのが特徴です。
たとえば「勉強時間6時間 → 合格確率82% → 50%を超えているので合格と判定」という流れです。 線形回帰が「売上は◯◯万円」と数値そのものを予測するのに対し、ロジスティック回帰は確率を経由してどちらのグループに属するかを予測します。 名前に「回帰」とありますが、この確率を計算する部分に回帰の仕組みを使っているためで、目的はあくまで分類です。
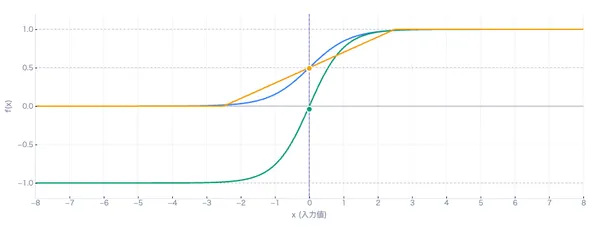
その仕組みは、線形回帰の出力をシグモイド関数(S字カーブ)に通して 0〜1の範囲に変換するというシンプルなものです。上のグラフの紫の曲線がまさにシグモイド関数で、オレンジの破線が「ここから右なら合格と判定する」境界線です。
📌ロジスティック回帰の特徴
- 📚教師あり学習・分類:「入力と正解ラベルのペア」から学ぶタイプの機械学習です。正解が「合格(1)/不合格(0)」のような2値になるのが特徴です。
- 📈確率を出力:単に「合格」「不合格」だけでなく、「合格する確率は75%」のように確率を返します。閾値を変えることで予測の感度を調整できます。
- ⚡解釈しやすい:「勉強時間が1時間増えると合格確率がどれだけ上がるか」を統計値エリアの「重み w」から読み取れます。w が大きいほど入力の変化が合格確率に強く影響します。
- 📐ボーダーラインで分ける:上のグラフのオレンジの破線が「合格/不合格のボーダーライン」です。たとえば勉強5時間がボーダーなら:
・5時間以上 → 合格予測
・5時間未満 → 不合格予測
とシンプルに分けます。ただしボーダーは直線なので、複雑な条件で合否が決まるデータには向きません。 - 🎯収束が速い:ニューラルネットワークなどの複雑なモデルに比べて、少ないエポック数で学習が完了します。上のツールでエポック数を動かすと、100回程度で損失がほぼ下がりきるのが確認できます。
📌ユースケース
📧 スパムフィルタ
Gmailなどのメールサービスで、メールの特徴から迷惑メールかどうかを確率で判定します。
🏥 医療診断
血液検査の数値などから病気の有無を予測。scikit-learnのLogisticRegressionが広く使われています。
💳 与信審査
クレジットカードの不正利用検知や、ローン審査の合否判定に利用されています。
📱 広告クリック予測
Google Adsなどの広告プラットフォームで、ユーザーが広告をクリックする確率を予測します。
📌用語解説
シグモイド関数(Sigmoid)
= どんな数値も「0%〜100%の確率」に変換するS字カーブ
= どんな数値も「0%〜100%の確率」に変換するS字カーブ
ロジスティック回帰の核となる関数で、任意の数値を0〜1の確率に変換します。 たとえば勉強時間から計算した値が100でも-50でも、この関数を通すと必ず0〜1の間に収まります。グラフの紫の実線がこのS字カーブです。数式: σ(z) = 1 / (1 + e-z) 入力が0のときちょうど0.5(五分五分)になります。
決定境界(Decision Boundary)
= 「合格」と「不合格」を分けるボーダーライン
= 「合格」と「不合格」を分けるボーダーライン
「合格」と「不合格」を分ける境目のことで、合格確率がちょうど50%になるポイントです。グラフのオレンジの破線がこれです。 たとえば「勉強時間5時間がボーダー」なら、5時間より多ければ合格予測、少なければ不合格予測になります。上のツールでエポック数を変えると、このボーダーラインの位置が変わっていく様子が見えます。
クロスエントロピー損失(Cross-Entropy Loss)
= 予測がどれだけハズレているかを数値化したもの
= 予測がどれだけハズレているかを数値化したもの
モデルの予測がどれだけ正解からズレているかを表す数値です。 実際に合格した人に対して「合格確率1%」と予測したら大ハズレなので損失は大きくなり、「合格確率99%」と予測できていれば損失は小さくなります。「学習の進行」セクションの赤い損失曲線がエポックごとの値です。学習が進むほど曲線が下がっていきます。数式: L = -(1/n) Σ [y·log(p) + (1-y)·log(1-p)]
学習率(Learning Rate, η)
= 1回の学習でどれだけ大きく修正するか
= 1回の学習でどれだけ大きく修正するか
学習時にパラメータを1回でどれだけ動かすかを決める設定値です。 大きくすると一気に修正するので速く学習できますが、行き過ぎて損失が逆に増えること(発散)があります。小さすぎるといつまでも学習が終わりません。上のツールでηを2.0にすると損失曲線がガタガタに振動するのが見えます。0.1〜1.0程度が一般的です。
勾配降下法(Gradient Descent)
= 坂を少しずつ下って一番低い谷を探す方法
= 坂を少しずつ下って一番低い谷を探す方法
損失を最小にするパラメータを見つけるための最適化アルゴリズムです。 山の上からボールを転がすイメージで、「今いる場所の坂の傾き」を計算し、坂が下る方向にパラメータ(w と b)を少しずつ動かします。これを繰り返すと損失が最も小さい場所(=最も予測がうまくいく場所)に近づきます。勾配の数式: ∂L/∂w = (1/n) Σ (p - y) · x
正解率(Accuracy)
= 全データのうち予測が当たった割合
= 全データのうち予測が当たった割合
全データのうち、モデルが正しく予測できた割合です。 20人中16人を正しく予測できたら正解率80%。最もわかりやすい指標ですが、合格者が極端に少ないデータでは「全員不合格」と言うだけで高い正解率が出てしまうので、精度や再現率と合わせて見る必要があります。計算式: (TP + TN) / 全データ数
精度(Precision)
=「合格」と予測した中で、本当に合格だった割合
=「合格」と予測した中で、本当に合格だった割合
モデルが「合格」と予測した人のうち、本当に合格だった割合です。 「このモデルが合格と言ったら、どれくらい信頼できるか?」を表します。たとえば合格と予測した10人中8人が本当に合格なら精度は80%です。計算式: TP / (TP + FP) FP(偽陽性)=不合格なのに合格と間違えた人数
再現率(Recall)
= 実際の合格者のうち、見つけられた割合
= 実際の合格者のうち、見つけられた割合
実際の合格者のうち、モデルが正しく「合格」と予測できた割合です。 「本当の合格者を取りこぼしていないか?」を表します。たとえば実際の合格者12人中8人を見つけられたら再現率は67%。病気の見逃しを防ぎたい医療診断では、再現率が特に重要視されます。計算式: TP / (TP + FN) FN(偽陰性)=合格なのに不合格と間違えた人数
混同行列(Confusion Matrix)
= 予測結果を4つに分類した表
= 予測結果を4つに分類した表
予測の当たり・ハズレを「予測×実際」の4パターンに整理した表です。 「学習の進行」セクションの右側に表示されています。TP(正しく合格と予測)・TN(正しく不合格と予測)が多いほど良いモデルです。FP(不合格を合格と誤判定)とFN(合格を不合格と誤判定)がエラーにあたります。
📌ロジスティック回帰の学習の流れ
1
パラメータを初期化
重み w=0、バイアス b=0 からスタート。このとき σ(0·x + 0) = 0.5 なので、すべてのデータに対して「合格確率50%」と予測する状態です。
🔁学習開始 — ステップ 2〜4 を指定したエポック数だけ繰り返す(1エポック = 全データを1周)
2
全員分の「合格確率」を予測する
各データに対して、今の w と b を使って合格確率を計算します。たとえば勉強時間3時間の人ならσ(w·3 + b) で確率が出ます。 最初は w=0, b=0 なので全員「50%」という適当な予測になります。
3
予測と正解を比べて「どっちにズレてるか」を調べる
全員分の「予測確率 − 正解ラベル」を集計して、w と b をどちらに動かせば予測が改善するかを計算します。この方向が「勾配」です。数式: ∂L/∂w = (1/n) Σ (予測 − 正解) · x
4
w と b を少しだけ修正する
ステップ3で求めた方向に、学習率 η の分だけ w と b を動かします。数式: w ← w − η · ∂L/∂wη が大きいと一気に修正、小さいとちょっとずつ修正。これを繰り返すたびに、グラフの紫の曲線がデータに合っていきます。
✓
収束して学習完了
繰り返すうちに損失がほぼ変化しなくなったら完了です。最終的にたとえば w=1.82, b=-9.12 が得られると、 ボーダーラインは「勉強約5時間」の位置になります。5時間以上勉強した人は合格、未満は不合格と予測するモデルの完成です。
📌線形回帰との比較
ロジスティック回帰は線形回帰の「親戚」です。中身の計算は似ていますが、出力をシグモイド関数で確率に変換することで分類問題に対応しています。
| 線形回帰 | ロジスティック回帰 | |
|---|---|---|
| 目的 | 数値を予測(回帰) | クラスを予測(分類) |
| 出力 | −∞ 〜 +∞ の連続値 | 0 〜 1 の確率 |
| 活性化関数 | なし(恒等関数) | シグモイド関数 σ(z) |
| 損失関数 | MSE(平均二乗誤差) | クロスエントロピー |
| 解法 | 正規方程式(一発) | 勾配降下法(反復) |
| 例 | 売上予測、気温予測 | スパム判定、合否予測 |
上のツールで学習率やエポック数を変えてみてください。線形回帰(OLS)は正規方程式で一発で解が出ますが、 ロジスティック回帰は反復的に最適解に近づいていくという違いがあります。 損失曲線パネルでその収束の様子が確認できます。