CLUSTERING VISUALIZER
K-Means法
「k個の重心にデータを振り分けて、重心を更新する」を繰り返す最も代表的なクラスタリング手法
解説
📌K-Means法とは
K-Means法は、データをk個のグループに分割する最も代表的なクラスタリング手法です。 「k個の旗を立てて、各データを最寄りの旗のグループにする。次に旗をグループの真ん中に移動する。」これを繰り返すだけのシンプルなアルゴリズムです。
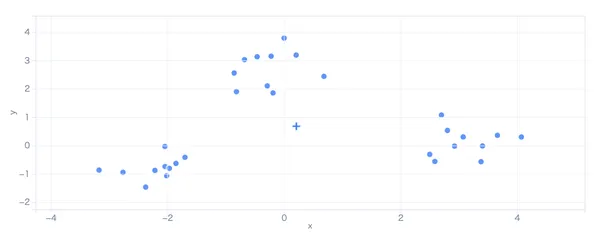
上のグラフでは、丸い点がデータ、十字マークが重心(旗)です。 「再生」ボタンを押すと、重心が移動しながらクラスタが安定していく過程をアニメーションで確認できます。破線は重心の移動軌跡です。
1957年にStuart Lloydが発案し、現在でもscikit-learn、Apache Spark、Google BigQuery MLなど主要なツールに標準搭載されている、最も広く使われるクラスタリング手法です。
📌K-Meansの特徴
- 🌳教師なし学習:正解ラベルなしで、データの散らばり具合だけからグループを発見します。「このデータにはどんなグループがあるか?」を探索する手法です。
- ⚡高速で大規模データに対応:計算量は O(n·k·t)(n=データ数, k=クラスタ数, t=反復回数)で、数百万件のデータでも数秒〜数分で処理できます。階層型クラスタリングの O(n³) と比較して圧倒的に速いです。
- 🎯kを事前に指定する必要がある:「何グループに分けるか」を先に決める必要があります。適切なkが分からない場合は、エルボー法(右下のグラフ)で最適なkの目安を見つけられます。
- ⚠️初期値に結果が依存する:初期重心の位置によって最終結果が変わります(局所最適解に陥る)。K-Means++初期化や複数回実行して最良結果を採用する方法で対策します。上のツールで「ランダム」に切り替えて何度か実行すると、結果が変わることを確認できます。
- ⭕球状のクラスタが得意:各データ点を「最も近い重心」に割り当てるため、結果的に球状(凸形状)のクラスタになります。三日月型や帯状など複雑な形のクラスタは苦手です。
- 📏スケールの影響を受ける:距離ベースの手法なので、特徴量のスケールが異なると、値の大きい特徴量に結果が支配されます。事前にStandardScalerなどで正規化することが重要です。
📌ユースケース
👥 顧客セグメンテーション
購買金額・頻度・最終購入日(RFM分析)で顧客を「優良顧客」「離反リスク」「新規」などにグループ分け。Amazon、楽天などのECサイトで広く使われています。
🎨 画像の色圧縮
画像の全ピクセルの色をk個のクラスタに分け、各ピクセルを最も近い代表色に置き換えます。16,777,216色→16色のような劇的な圧縮が可能。GIFの色数削減にも使われます。
📍 施設の最適配置
配送センターや店舗の立地最適化。顧客の住所データをK-Meansでクラスタリングし、各重心の位置に施設を配置すると総移動距離が最小になります。
📊 異常検知の前処理
正常データをクラスタリングし、どのクラスタの重心からも遠い点を異常値として検出。ネットワーク侵入検知やセンサーデータの品質管理に活用されます。
📌用語解説
重心(Centroid)
= クラスタの「中心点」
= クラスタの「中心点」
クラスタに属する全データ点の座標の平均値です。グラフの十字マークが重心です。 K-Meansでは、この重心の位置を繰り返し更新することでクラスタを最適化します。数式: c = (1/n) Σ xᵢ (クラスタ内の全点の平均)具体例: クラスタ内の点が (1,2), (3,4), (2,6) なら → 重心 = ((1+3+2)/3, (2+4+6)/3) = (2.0, 4.0)
SSE(Sum of Squared Errors)
= クラスタ内の散らばりの合計
= クラスタ内の散らばりの合計
各データ点から自分が属するクラスタの重心までの距離の二乗を全部足したものです。 K-Meansはこの値を最小化するように重心を動かします。SSEが小さいほど、各クラスタのまとまりが良いということです。数式: SSE = Σᵢ ||xᵢ − c(xᵢ)||²
エルボー法(Elbow Method)
= 最適なkを見つけるための手法
= 最適なkを見つけるための手法
k=1,2,3,...とクラスタ数を増やしながらSSEをプロットすると、ある点で急に減少が緩やかになります。 このグラフが「肘(エルボー)」のように折れ曲がる点が、データの自然なグループ数の目安です。kを増やせばSSEは必ず減りますが、意味のないグループ分割になります。エルボー点は「SSEの減少がコスト(クラスタ数の増加)に見合わなくなる点」です。上のツールで「5群」データに切り替え、右下のエルボー法グラフでk=5付近に肘が見えることを確認してください。
K-Means++(初期化の改良版)
= 初期重心を「遠く」に配置する戦略
= 初期重心を「遠く」に配置する戦略
ランダム初期化では重心が偏った位置に配置されることがあり、不適切な結果になりがちです。 K-Means++は最初の1つをランダムに選び、2つ目以降は既存の重心から遠い点ほど高い確率で選ばれるようにします。これにより初期重心がデータ全体に分散して配置され、収束が速く、より良い結果が得られます。 scikit-learnのKMeansのデフォルト初期化方式です。上のツールで「ランダム」と「K-Means++」を切り替えて数回ずつ実行すると、K-Means++の方がSSEが低く安定することが分かります。
イテレーション(Iteration)
= 「割り当て→重心更新」を1回行うこと
= 「割り当て→重心更新」を1回行うこと
K-Meansは「各点を最も近い重心に割り当て → 重心を再計算」のサイクルを繰り返します。 この1サイクルが1イテレーションです。 イテレーション0は初期配置で、1以降が実際の更新です。上のツールのスライダーでイテレーションを1つずつ進めると、重心が移動してクラスタの割り当てが変わる様子が確認できます。
クラスタ数 k
= データを何グループに分けるかの指定値
= データを何グループに分けるかの指定値
K-Meansではkを事前に指定する必要があります。アルゴリズムが自動で決めてくれるわけではありません。 kが小さすぎると本来別のグループが1つに混ざり、大きすぎると1つのグループが不自然に分割されます。最適なkを選ぶにはエルボー法が使われます。上のツールでkを1〜8に変えて、チャートの分割の変化とSSEの推移を観察してみてください。
収束(Convergence)
= 重心がもう動かなくなった状態
= 重心がもう動かなくなった状態
イテレーションを繰り返すと、やがてどのデータ点もクラスタを変えなくなり、重心の位置も変わらなくなります。 この状態を「収束した」と言います。上のステータスに「収束済み」と表示されたら、それ以上反復しても結果は変わりません。収束までの回数はデータと初期化方法で大きく変わります。クラスタが明確に分かれているデータ+K-Means++初期化なら2〜3回で収束しますが、クラスタが不明確なデータやランダム初期化では10回以上かかることもあります。上のツールで初期化方法やデータセットを切り替えて違いを確認してみてください。
📌K-Meansの手順
1
k個の初期重心を配置する
k=3の場合、3つの初期重心を配置します。K-Means++ではデータ全体に分散するように配置され、ランダムではデータ点の中からランダムに3つ選ばれます。 例: 重心 C₁(−1,2), C₂(4,0), C₃(0,−3) の3つからスタートします。
🔁ステップ 2〜3 を、重心が動かなくなるまで繰り返します(通常10〜30回で収束)
2
各データ点を最も近い重心に割り当てる
各データ点からすべての重心までの距離を計算し、最も近い重心のクラスタに割り当てます。 この時点でボロノイ分割(各重心が「縄張り」を持つ空間分割)が形成されます。
3
各クラスタの重心を再計算する
各クラスタに属するデータ点の平均座標を計算し、重心を移動します。 例: クラスタ1の点が (1,2), (3,4), (2,0) なら → 新しい重心 = (2.0, 2.0)。 上のグラフの破線が重心の移動軌跡です。 この移動がなくなれば収束です。
4
収束したら完了
重心が動かなくなった(=どのデータ点もクラスタを変えなくなった)ら完了です。 最終的に各データ点は最も近い重心のクラスタに属し、SSEが(局所的に)最小化された状態になっています。 結果: k個のクラスタと、その重心の座標が得られます。
📌K-Means++ — なぜ初期値が重要なのか
K-Meansの結果は初期重心の配置で大きく変わります。 ランダム初期化では、重心が1箇所に偏ってしまうことがあり、その場合は本来のクラスタを見つけられずに収束してしまいます。 K-Means++は2006年にArthurとVassilvitskiiが提案した初期化方法で、この問題を解決します。
ランダム初期化の問題
偏った初期配置
右のクラスタを正しく認識できず、不自然な分割になる
K-Means++の初期配置
最初からクラスタに近い位置にあるため、少ないイテレーションで収束する
K-Means++のアルゴリズム
1
最初の重心をランダムに1つ選ぶ。データ点の中から1つをランダムに選び、最初の重心 C₁ とする。
2
各点からC₁までの距離²を計算し、距離²に比例する確率で次の重心を選ぶ。C₁から遠い点ほど高い確率で選ばれる。例: 距離²が100の点は、距離²が10の点より10倍選ばれやすい。
3
k個の重心が揃うまでステップ2を繰り返す。3つ目以降は「最も近い既存重心までの距離²」を使うため、既存の重心群から離れた場所が優先的に選ばれます。
なぜ距離²(二乗)を使う? 距離そのものではなく二乗を使うことで、遠い点がさらに強調されます。 例えば距離10の点と距離2の点では、距離の比は5倍ですが、距離²の比は25倍です。 これにより重心同士が確実に離れるようになります。
K-Means++はscikit-learn・Apache Spark・Rなど主要なライブラリでデフォルトに採用されています。 上のツールで「ランダム」と「K-Means++」を切り替え、SSEの安定性と収束回数の違いを確認してみてください。
📌K-Meansと階層型クラスタリングの比較
| 観点 | K-Means | 階層型 |
|---|---|---|
| kの指定 | 必要(事前に決める) | 不要(後から決められる) |
| 計算量 | O(n·k·t) — 高速 | O(n³) — 大規模データに不向き |
| 結果の再現性 | 初期値依存(毎回異なる可能性) | 決定的(毎回同じ結果) |
| クラスタ形状 | 球状(凸形状)のみ | リンケージ法により柔軟 |
| デンドログラム | なし | あり(階層構造を可視化) |
| 大規模データ | 数百万件でもOK | 数千件が限界 |
使い分けの目安:データが大きい・クラスタ数の目安がある → K-Means。 データが小さい・階層構造を見たい・kが不明 → 階層型。 両方試して結果を比較するのが実務では一般的です。