ReLU系活性化関数の比較
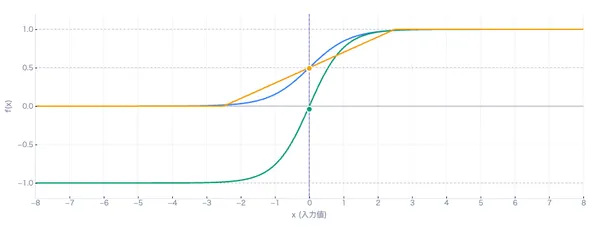
ニューラルネットワークの各ニューロンに使われる活性化関数を比較します。ReLUを基本として、その弱点を克服するために生まれた6つの関数を重ねて表示し、形状や導関数の違いを直感的に理解できます。
🧠活性化関数とは
活性化関数は、ニューラルネットワークの各ニューロンが「入力の信号をどう変換して次に渡すか」を決める関数です。 人間の脳の神経細胞が「一定以上の刺激で発火する」のと同じように、入力が小さければ抑え、大きければ通す — というフィルターの役割を果たします。もし活性化関数がなければ、ニューラルネットワークは何層重ねても単純な直線(一次関数)しか表現できません。 活性化関数が非線形性を導入することで、曲線や複雑なパターンを学習できるようになります。
⚡なぜReLU系が主流なのか
- 📉Sigmoid/tanhの問題:かつて主流だったSigmoidやtanhは、入力が大きくなると導関数がほぼ0になります。深い層まで勾配が伝わらず学習が進まない — これが勾配消失問題です。上のツールで導関数グラフを見ると、ReLU系はx>0で勾配が1に近く安定していることがわかります。
- 🚀ReLUの登場:2012年のAlexNetがReLUを採用して画像認識で圧勝。max(0, x) という極めてシンプルな計算で、Sigmoidより6倍速く学習が収束しました。以来、ReLUがデフォルトの選択肢になっています。
- 💀Dying ReLU問題:ReLUはx<0で出力も勾配も完全に0になるため、一度「死んだ」ニューロンは二度と復活しません。上のツールでReLUだけ表示し、x<0の領域を見ると、出力も導関数も完全に0であることが確認できます。Leaky ReLU以降の関数はこの問題を解決するために生まれました。
📊各関数の特徴比較
| 関数 | 式 | 負の領域 | 滑らかさ | 主な用途 |
|---|---|---|---|---|
| ReLU | max(0, x) | 完全に0(不活性化) | ×(角がある) | CNNの隠れ層全般 |
| Leaky ReLU | max(αx, x) | αx(小さく残る) | ×(角がある) | GANなど |
| ELU | α(eˣ-1) | -αに飽和 | ○(滑らか) | 深いネットワーク |
| GELU | x·Φ(x) | 少し負になる | ◎(完全に滑らか) | BERT, GPT, ViT |
| Swish | x·σ(βx) | 少し負になる | ◎(完全に滑らか) | EfficientNet |
| Mish | x·tanh(sp(x)) | 少し負になる | ◎(完全に滑らか) | YOLOv4 |
📖用語解説
= ニューロンの出力を変換する関数
= 関数の「傾き」を表す関数
= 導関数が0に近づき学習が止まる現象
= ニューロンが永久に出力0になる問題
= 出力の平均が0に近い性質
= 関数にカクッとした角がないこと
🧭どの活性化関数を選ぶべきか
📜活性化関数の歴史と進化
1ReLU(Rectified Linear Unit)
2012年の画像認識コンペ(ImageNet)でAlexNetが採用し、ディープラーニングのブレイクスルーを起こした活性化関数です。 現在もCNNの隠れ層で最も広く使われています。
f(0) = max(0, 0) = 0
f(-3) = max(0, -3) = 0
2Leaky ReLU
ReLUのDying ReLU問題を最もシンプルに解決した関数です。 「漏れのある(Leaky)ReLU」という名前の通り、負の領域でも信号を少しだけ漏らします。 GAN(敵対的生成ネットワーク)で特によく使われます。
f(x) = α · x (x ≤ 0)
f(-3) = 0.1 × (-3) = -0.3(ReLUなら0だが、-0.3が残る)
f(-10) = 0.1 × (-10) = -1.0
3ELU(Exponential Linear Unit)
Leaky ReLUが直線で負の領域を処理するのに対し、ELUは指数関数(exponential)を使って滑らかに処理します。 出力の平均がゼロに近くなる性質があり、深いネットワークで学習が安定しやすくなります。
f(x) = α · (eˣ - 1) (x ≤ 0)
f(-1) = 1.0 × (e⁻¹ - 1) = 1.0 × (0.368 - 1) = -0.632
f(-5) = 1.0 × (e⁻⁵ - 1) = 1.0 × (0.007 - 1) ≈ -0.993(-1に近づく)
4GELU(Gaussian Error Linear Unit)
BERT・GPT・Vision Transformerなど、現在の大規模モデルで最も広く使われている活性化関数です。 「入力が正規分布に従うとき、大きな値ほど通しやすく、小さな値ほど抑える」という確率的な考え方に基づいています。
※ Φ(x) は正規分布の累積分布関数
f(0) = 0 × Φ(0) = 0 × 0.5 = 0
f(-1) = -1 × Φ(-1) = -1 × 0.159 ≈ -0.159(少しだけ負)
f(-3) = -3 × Φ(-3) = -3 × 0.001 ≈ -0.004(ほぼ0)
5Swish / SiLU(Sigmoid Linear Unit)
2017年にGoogle Brainが自動探索(NAS)で発見した活性化関数です。 人間が設計したのではなく、「どんな数式が最も性能が良いか」を機械に探させた結果、この式が見つかりました。 β=1 のとき SiLU(Sigmoid Linear Unit)とも呼ばれます。EfficientNetで採用されています。
※ σ(x) = 1/(1+e⁻ˣ) はシグモイド関数
f(0) = 0 × σ(0) = 0 × 0.5 = 0
f(-1) = -1 × σ(-1) = -1 × 0.269 ≈ -0.269
f(-5) = -5 × σ(-5) = -5 × 0.007 ≈ -0.034(ほぼ0に戻る)
6Mish
2019年にDiganta Misraが提案した、Swishの改良版です。 物体検出で有名なYOLOv4に採用され、画像認識タスクでSwishやReLUを上回る精度が報告されています。 調整すべきパラメータがなく、そのまま使えるのも利点です。
= x · tanh(ln(1 + eˣ))
f(0) = 0 × tanh(ln(2)) = 0 × 0.600 = 0
f(-1) = -1 × tanh(ln(1+e⁻¹)) = -1 × tanh(0.313) ≈ -0.303
f(-5) ≈ -5 × tanh(0.007) ≈ -0.034