線形回帰 (Linear Regression)
勾配降下法でデータに最もフィットする直線を見つける、機械学習の最も基本的なアルゴリズム
📌線形回帰とは
線形回帰は、過去のデータをもとにまだ見ぬ数値を予測する手法です。 たとえば「広告費を30万円かけたら、売上はいくらになるか?」という問いに対して、 過去の広告費と売上のデータからŷ = w·x + b という直線を学習し、「売上は約105万円になりそう」と予測します。
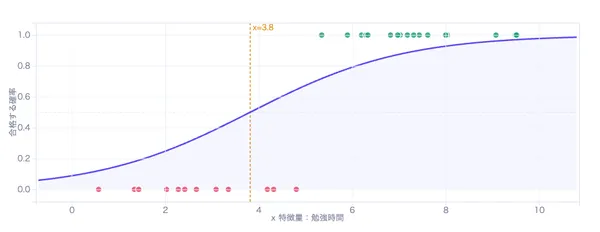
ロジスティック回帰が「合格か不合格か」の分類をするのに対し、 線形回帰は「売上は◯◯万円」「気温は◯◯度」のように具体的な数値を予測します。 この「数値を予測する」タスクのことを機械学習では回帰と呼びます。
直線の良さは「予測と実際の誤差がどれだけ小さいか」で測ります。この誤差をコスト関数(MSE)と呼び、 これを最小にする傾き w と切片 b を見つけるのが目標です。
最適な w と b の求め方には2つの方法があります。解析解(正規方程式)は数式で一発で正解を出す方法で、データが少なければこれで十分です。 もう1つが勾配降下法で、少しずつ誤差を減らしながら正解に近づけていく方法です。 データが大量にあるときや、ニューラルネットワークなど複雑なモデルでは勾配降下法が使われます。 このツールでは両方を体験できます。
⚡線形回帰の特徴
- 📚教師あり学習:「入力と正解のペア」から学ぶタイプの機械学習です。たとえば「広告費→売上」のデータを渡すと、広告費からまだ見ぬ売上を予測できる直線を学習します。上のツールでピンクの直線がこの予測線です。
- ⚡解析解が存在する:正規方程式を使えば w = (XᵀX)⁻¹Xᵀy と一発で最適解が求まります(上のツールの緑の破線)。ただしデータが巨大になると逆行列の計算がボトルネックになるため、実務では勾配降下法が使われます。
- 🎯コスト関数が凸関数:MSEのグラフは「お椀型」なので、局所解がなく、どこから始めても谷底にたどり着けるのが線形回帰の嬉しい性質です。上のツールの等高線図で初期値を変えても、最終的に同じ点に収束することを確認してみてください。
- 📏解釈性が高い:係数 w は「x が1単位増えると y が w だけ増える」という直感的な意味を持ちます。ディープラーニングのような「ブラックボックス」と違い、結果を人間が解釈しやすいのが強みです。
- ⚠️非線形な関係には弱い:データの関係が曲線的(例:2次関数や指数的な増加)な場合、直線ではうまくフィットできません。その場合は多項式回帰やニューラルネットワークを検討します。
🏢線形回帰のユースケース
📖用語解説
= x が1増えたとき y がどれだけ増えるか
= x = 0 のときの y の値
= 予測がどれだけ外れているかの指標
= モデルがデータをどれだけ説明できるか
= 1ステップでどれだけパラメータを動かすか
= パラメータの更新回数
= コスト関数の傾き
= パラメータ空間でのコスト関数の地形
🪜勾配降下法による線形回帰の学習の流れ
8社の広告費と売上のデータから、y = w·x + b の最適な w と b を勾配降下法で求める流れを見ていきましょう。
(10, 52), (15, 68), (20, 75), (25, 90), (30, 102), (35, 110), (40, 125), (45, 138)
例えば (10, 52) は「広告費10万円のとき売上52万円」という意味です。
次に、直線の傾き(w)と切片(b)の初期値を決めます。 ここでは w = 0, b = 0(まっさらな状態)からスタートします。 ただし実際には、データの傾向を見てある程度妥当な初期値を設定するのが望ましいです。 最適解に近い初期値を選べば学習回数(エポック数)が少なく済み、効率よく収束します。
w ≈ 2.45(解析解: 2.47)、b ≈ 28.9(解析解: 29.2)
学習によって得られた直線 ŷ = 2.45x + 29 が、データ全体の傾向を表す線形回帰の回帰直線になります。
つまり「広告費を1万円増やすと売上が約2.45万円増える」と予測できます。 R² ≈ 0.99 なので、広告費で売上の変動の99%を説明できている、非常に良いフィットです。
⚖️解析解 vs 勾配降下法
- • 一発で最適解が求まる
- • ハイパーパラメータ不要
- • 逆行列の計算が必要(O(n³))
- • データが大量だと計算コスト大
- • メモリにデータ全部を載せる必要あり
- • 反復的に最適解に近づく
- • 学習率・エポック数の調整が必要
- • 各ステップは O(n) で軽い
- • 大規模データでもスケール可能
- • ミニバッチで少量ずつ処理可能
💡たとえ話で理解する:勾配降下法
勾配降下法は、予測の誤差(コスト)を最小にするパラメータ w と b を見つけるためのアルゴリズムです。 「霧の中で山の谷底を探す」ことに似ています。
あなたは霧の中で山の斜面に立っています。周りが見えないので、谷底がどこにあるかわかりません。 でも、足元の傾き(勾配)だけは感じ取れます。 「足元が左に傾いている → 左に進む」「右に傾いている → 右に進む」を繰り返せば、いつか谷底にたどり着きます。
上のツールの等高線図がまさにこの「山」です。色が薄い場所が谷底、ピンクの軌跡があなたの歩いた道。学習率を大きくしすぎると歩幅が大きすぎて谷底を飛び越えてしまい、小さすぎると谷底にたどり着くまでに時間がかかります。試してみてください。
💡たとえ話で理解する:解析解
解析解(正規方程式)は、数式を使って一発で最適な答えを出す方法です。 「地図を見て谷底の座標を計算する」ことに似ています。
霧なんて関係ありません。山全体の地図(=データ全体)を手に入れて、数学の公式で「谷底はここ」と一発で求めます。 歩き回る必要がないので、学習率もエポック数も不要です。
ただし、地図を作るのにも計算コストがかかります。データが大量(100万件〜)になると地図を作ること自体が大変になるため、 そういう場合は霧の中を歩く方法(勾配降下法)のほうが現実的です。