ALGORITHM VISUALIZER
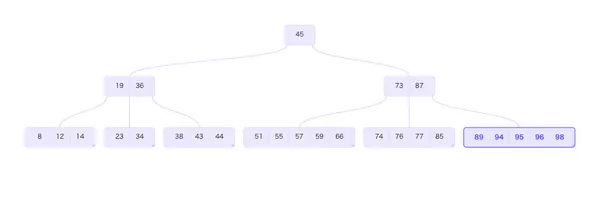
B-Tree 検索
B-Treeの検索アルゴリズムをステップごとに可視化します。値を入力して検索経路を確認してください。
検索
ツリー内の値:
ツリー外の値:
ステップ制御
下のボタンから値を選んでください
ツリー情報
次数 (t)2
最大キー数3
高さ3
総キー数17
現在訪問中のノード
発見したキー
比較で停止したキー(ここより左の子へ)
通過したキー(これより大きい)
解説
📌B-Tree検索とは
図書館の本棚を想像してください。本を探すとき、棚ごとに「あ〜さ行」「た〜な行」と書かれたラベルを見て、目的の棚に一直線に向かいます。B-Treeの検索はまさにこの仕組みです。ルートのノードが「棚のラベル」の役割を果たし、 値の大小比較だけで次に見るべきノードが決まります。
1ノードに複数のキーが入っているため、1回の比較で複数の子ノードを一気に除外できます。 二分探索木と違い常に整列・平衡が保証されているので、どのデータを探しても必ず同じ深さで答えにたどり着けるのがB-Treeの大きな特徴です。
✅B-Tree検索の特徴
- 🎯常にルートから開始する。どの値を探すときも必ず最上段のノードから始まる。これにより探索経路が一定で予測しやすい。
- ⚡計算量はO(log n)。1,000万件のデータでも高さ25以下でたどり着ける。全件スキャンのO(n)と比べて圧倒的に速い。
- 📦1ノードに複数キーがあるため「絞り込み効率」が高い。キー1つの比較でノード内の全キーを参照し、次の子を決定できる。
- ⚖️自動でバランスを保つ(自己平衡)。データを挿入・削除しても木が自動で再構成され、すべての葉が常に同じ深さに保たれる。二分探索木は挿入順次第で偏りが生じ最悪O(n)になるが、B-Treeはどんな場合でもO(log n)が保証される。
🗺️どこで使われているか
📚 辞書・索引検索
紙の辞書や百科事典の索引と同じ仕組み。「あ〜さ行」のような境界値で一気に候補を絞り込み、目的のページへたどり着く。B-Treeの原点となる考え方。
📁 ファイルシステム
ext4・NTFS・APFSなどがファイルのパス管理にB-Tree系を採用。数十万ファイルの中から目的のファイルを瞬時に見つけられる理由。
🗄️ データベースインデックス
MySQL(InnoDB)・PostgreSQL・SQLiteが行の検索に使う。テーブルに数百万行あっても数回のノード参照で目的の行にたどり着ける。
🔍 NoSQL(ドキュメントDB)
MongoDBはデフォルトのインデックスにB+Tree(B-Treeの派生)を採用。コレクションに大量ドキュメントがあっても高速に検索できる。なおRocksDB・LevelDBはLSM-Treeという別の構造を使う。
🔑 ユニーク制約チェック
データ挿入時に「同じキーがすでに存在しないか」をB-Tree検索で確認する。インデックスが整合性の担保も兼ねる。
🗓️ 時系列・ログ管理
時刻をキーにしたB-Treeで「この時間帯のログをすべて取得」といった範囲検索が効率よく行える。監視ツールやDBのWALで活用される。
📖用語解説
ルートノード
木の最上段にある唯一のノード。すべての検索はここから始まる。図書館でいう「フロアマップ」にあたる。
内部ノード
ルートと葉の間にあるノード。複数のキーを持ち、それぞれのキーが「境界値」として子ノードへの道を示す。
葉ノード(リーフ)
子ノードを持たない最下段のノード。すべての葉は同じ深さにある。ここで見つからなければ検索失敗。
子ポインタ(検索経路)
キーとキーの「間」にある子へのリンク。キーが2つのノードには子が3つある。検索値と境界キーを比較してどのポインタを辿るか決める。
🔍検索の手順(例: 15を探す)
1
ルートノード [30] を確認
15 < 30 なので左の子(child[0])へ降りる。
2
内部ノード [10, 20] を確認
15 > 10 なので通過。15 < 20 なので child[1] へ降りる。
3
葉ノード [15, 18] を確認 → 発見!
15 = 15 で一致。検索成功。合計3ノードを訪問した。
4
見つからない場合(葉で終了)
葉ノードまで降りてもキーが一致しなければ検索失敗。ツリー内に存在しないと確定する。
⚡計算量と他の構造との比較
線形探索
O(n)
先頭から1件ずつ確認する実装は最もシンプルデータ数に比例して遅くなる
こういう時に使う
•Python list.index()・JS Array.find() がこれ
•数十件程度の小さいデータ、一度きりの検索
•大規模システムで単体採用される場面はほぼない
二分探索木(BST)
O(log n)*
1ノードに1キーの木構造平均O(log n)で高速偏ると最悪O(n)になる
こういう時に使う
•C++ std::map・std::set(内部は Red-Black Tree)
•Java の TreeMap・TreeSet
•実用では平衡化(AVL・赤黒木)した派生版が使われ、素朴なBSTは教育目的以外ではほぼ使われない
ハッシュテーブル
O(1)**
完全一致検索はO(1)範囲検索・順序が苦手衝突が起きると遅くなる
こういう時に使う
•Redis・Memcached のKVS
•Python dict・JS Map
•PostgreSQL の Hash Join(EXPLAIN で確認できる)
•完全一致のみ・範囲検索や ORDER BY が不要な場合に最適
B-Tree検索(今回)
O(log n)
常にO(log n)で安定範囲検索・順序にも対応自己平衡で偏りが生じない
こういう時に使う
•PostgreSQL・MySQL(InnoDB)・SQLite のインデックス
•MongoDB のドキュメントインデックス
•macOS APFS のファイルシステム
•範囲検索・ORDER BY・ユニーク制約に強く、RDB インデックスの事実上の標準
| データ構造 | 探索 | 挿入 | 削除 |
|---|---|---|---|
| 線形探索 | O(n) | O(1) | O(n) |
| 二分探索木 | O(log n)* | O(log n)* | O(log n)* |
| ハッシュ | O(1)** | O(1)** | O(1)** |
| B-Tree | O(log n) | O(log n) | O(log n) |
* 偏った場合は最悪O(n) ** 衝突が多い場合は最悪O(n)