ALGORITHM VISUALIZER
B-Tree
データベースや索引で使われる、挿入・検索・削除をすべて O(log n) で実現する自己平衡型の多分木構造
設定
次数 (t)
挿入
自動再生
スピード1.2秒
統計
0
総キー数
0
ノード数
0
高さ
0
分割回数
凡例
通常ノード
挿入されたキー
分割されたノード
操作ログ
操作なし
解説
📌B-Treeとは
B-Tree は、データベースのインデックス(索引)として世界中で使われているデータ構造です。 500ページの本から「データベース」という単語を探すとき、1ページ目から全部めくるのは大変です。でも巻末の索引を使えば「→ 243ページ」とすぐわかります。B-Tree はこの「索引」の仕組みをコンピューター向けに最適化したもので、MySQL・PostgreSQL・SQLite などのデータベースや、ext4・NTFS などのファイルシステムで採用されています。
すべての葉ノードは同じ深さにあり、木の高さは常に O(log n) に保たれます。データが 100万件あっても高さ20以下で目的のデータにたどり着けます。
✅B-Treeの特徴
- 🌿すべての葉ノードは常に同じ深さにある。普通の二分木はデータの追加順によって左右どちらかに偏ってしまうことがあるが、B-Treeでは分割と結合のルールによってどんなデータを入れても木が左右均等に保たれる。そのため、最悪ケースでも検索速度が劣化しない。
- 📦1つのノードに複数のデータを詰め込める。二分木は1ノードにデータ1つだけだが、B-Treeは数十〜数百個をまとめて格納できる。その結果、木の高さが非常に低くなり、少ないステップで目的のデータにたどり着ける。たとえば次数1000のB-Treeなら、10億件のデータでも高さはたった3程度になる。
- ⚡探索・挿入・削除がすべてO(log n)。O(log n)とは「データ量が10倍に増えても、手順は1ステップ増えるだけ」という意味。100万件でも高さ20以下、1億件でも高さ30以下で目的のデータに到達できるので、データ量が膨大になっても検索速度がほとんど変わらない。
- 💾1ノード=ディスクの1ブロックに対応させる設計。HDDやSSDはデータを「ブロック」という単位で読み書きする。B-Treeは1ノードのサイズをこのブロックに合わせることで、1回のディスク読み込みで1ノード分のデータをまるごと取得できる。ディスクアクセスはメモリの10万倍以上遅いので、アクセス回数を最小にできるこの仕組みがデータベースやファイルシステムに採用される理由。
- 🔀ノードが満杯になると自動で分割(Split)される。たとえば最大3つのキーを持てるノードに4つ目を入れようとすると、真ん中のキーを親に押し上げて2つのノードに分かれる。この分割が連鎖的に上へ伝わることもあり、ルートまで分割が届いたときだけ木の高さが1段増える。逆にデータの削除時はノードの結合(Merge)が起きる。
どんな場面で使われているか
🗄️ RDBのインデックス
MySQL(InnoDB)・PostgreSQL・SQLiteが採用。WHERE句で絞り込むときに裏側で動いている。
📁 ファイルシステム
ext4・NTFS・HFS+がファイルの場所を管理するためにB-Tree系を使用。
🔍 NoSQL / KVS
MongoDBのデフォルトインデックス、RocksDB(LevelDB)などでも採用。
📊 OSのページ管理
Linuxカーネルが仮想メモリのアドレス空間管理にred-black tree(B-Tree派生)を使用。
📖用語解説
ノード(Node)
B-Treeを構成する「箱」のこと。1つのノードに複数のキーを入れられ、キーの数+1個の子ノードへのポインタを持つ。
ルートノード(Root)
木の一番上にある出発点の箱。検索や挿入は必ずここから始まる。B-Tree全体に1つだけ存在する。
リーフノード(Leaf)
木の一番下にある末端の箱。子ノードを持たない。B-Tree では全リーフが必ず同じ深さに並ぶ。
内部ノード(Internal Node)
ルートとリーフの間にある中間の箱。子ノードへの道案内(ポインタ)を持つ。ルートも広義では内部ノードの一種。
キー(Key)
各ノードの中に入っているデータ(数値や文字列)。ノード内では必ず昇順に並び、左の子より大きく右の子より小さい。
子ノード(Child Node)
あるノードの直下につながっているノード。逆に「上につながっているノード」を親ノードと呼ぶ。データが k 個あるノードは、ちょうど k+1 個の子ノードを持つ。
高さ(Height)
ルートから一番下のリーフまで何段あるか、を表す数。
B-Tree ではすべてのリーフが必ず同じ段に揃うようにデータを自動整理する(「右は3段、左だけ5段」という偏りが起きない)。
段が1つ増えると格納できるデータ量が一気に増えるため、データが何百万件あっても高さは数十段で収まる。
B-Tree ではすべてのリーフが必ず同じ段に揃うようにデータを自動整理する(「右は3段、左だけ5段」という偏りが起きない)。
段が1つ増えると格納できるデータ量が一気に増えるため、データが何百万件あっても高さは数十段で収まる。
💡 計算の仕組み各ノードは子ノードを最大 2t 個持てるので、段が1つ増えるたびにノード数が最大 2t 倍になる。
全段のノード数の合計は等比数列の和で求められる:
1 + 2t + (2t)² + … + (2t)ʰ⁻¹ = ((2t)ʰ − 1) / (2t − 1)各ノードには最大 2t − 1 個のデータが入るので、最大データ数は:
((2t)ʰ − 1) / (2t − 1) × (2t − 1) = (2t)ʰ − 1t=2 を代入すると (2×2)ʰ − 1 = 4ʰ − 1(上の表の値)
全段のノード数の合計は等比数列の和で求められる:
1 + 2t + (2t)² + … + (2t)ʰ⁻¹ = ((2t)ʰ − 1) / (2t − 1)各ノードには最大 2t − 1 個のデータが入るので、最大データ数は:
((2t)ʰ − 1) / (2t − 1) × (2t − 1) = (2t)ʰ − 1t=2 を代入すると (2×2)ʰ − 1 = 4ʰ − 1(上の表の値)
🔢次数 t とキー数のルール
次数 t は「1つのノードにデータを何個まで入れていいか」を決める数です。t が大きいほど1つの箱にたくさん詰め込めます。
💡 なぜ「データの数 + 1個」の子ノードが必要?[ 10 | 30 | 50 ]このノードにデータが3つあると、「10より小さい」「10〜30の間」「30〜50の間」「50より大きい」という 4つの行き先(子ノード) ができます。データが k 個あれば、すき間は k+1 個になるためです。
このデモでは t = 2, 3, 4 を選べます。まず t = 2 で試してみて、数字を追加するたびにノードが満杯になり、分割が起きる様子を確認してみましょう。
🪜挿入の手順
1
どの葉ノードに入れるか探す
ルートから「入れたい数 > ノードの値?」で左右どちらへ進むか決める。リーフに着くまで繰り返す。
2
葉ノードに挿入
リーフノードに小さい順を保ちながら追加する。空きがあればここで完了!
3
満杯なら分割(Split)
ノードが満杯(2t−1個)になったら、真ん中のキーを親へ送り上げ、ノードを左右2つに分ける。
4
親も満杯なら上へ連鎖
真ん中を受け取った親も満杯になったら、同じ分割がさらに上へ伝わる。ルートが分割されて初めて木の高さが1段増える。
✂️ノード分割(Split)の仕組み
// 例)t=2、10〜50を順に挿入して [ 10 | 20 | 30 ] のノードに 40 を入れようとする
[ 10 | 20 | 30 ] ← keys = 2t−1 = 3 で満杯!
// 真ん中のキー(20)を親に送り上げて左右に分割
親に昇格:[ 20 ]
左の子 :[ 10 ] 右の子:[ 30 | 40 ]
[ 10 | 20 | 30 ] ← keys = 2t−1 = 3 で満杯!
// 真ん中のキー(20)を親に送り上げて左右に分割
親に昇格:[ 20 ]
左の子 :[ 10 ] 右の子:[ 30 | 40 ]
💡 ルート分割の特別なケースルートが満杯になったときは特別です。空の新しいルートを作り、もとのルートをその子として分割します。これが木の高さが増える唯一の場面です。上のデモで「分割回数」カウンターを見ながら確認してみましょう!
📊計算量と他のデータ構造との比較
BST(二分探索木)
左の子は必ず小さく、右の子は必ず大きい、という決まりの二分木。「1, 2, 3, 4…」と順に追加すると右だけに伸びて一直線になってしまう。最悪の場合、探すたびに全データをたどることになり遅い。
AVL木
BSTに「自動バランス調整」を加えた二分木。左右の高さがずれると、ノードを「回転」させて均等に直す。どんな順で追加してもO(log n)を保てるが、1ノード1キーのため木が深くなりやすい。
B-Tree
1つのノードに複数のキーと子を詰め込める多分木。たくさん詰め込めるぶん木の高さが低く、少ない段数でデータにたどり着ける。1ノード = ディスクの1ブロックに対応させると読み込み回数を大幅に減らせる。
B+Tree
B-Treeの改良版。実際のデータはすべて葉ノードだけに置き、内部ノードは道案内専用にする。葉ノード同士が横に連結リストでつながっているため、範囲検索(例:20〜50)が得意。MySQLやSQLiteのインデックスはこの構造を使っている。
💡 実際のDBで使われているのは B+Tree現代のデータベースのほとんどは B-Tree ではなく B+Tree をインデックスに採用しています。 MySQL(InnoDB)・PostgreSQL・SQLite・Oracle など、主要なDBはほぼすべてB+Treeです。理由の1つ目はノードに入るキーが増えること。B+Treeの内部ノードはデータを持たず道案内専用なので、同じノードサイズにより多くのキーを詰め込めます。その分だけ木の高さが低くなり、ディスクへのアクセス回数をさらに減らせます。理由の2つ目は範囲検索が速いこと。葉ノードが連結リストでつながっているため、「20以上50以下を全部取り出して」という検索が、葉を左から右へなぞるだけで完了します。B-Treeではこの操作に何度もルートに戻る必要があり非効率です。
関連コンテンツ
ハッシュインデックス((Hash Index))
ハッシュ関数で高速にデータを検索するインデックス構造
ブルームフィルタ(Bloom Filter)
確率的データ構造。要素の存在を高速・省メモリで判定(偽陽性あり・偽陰性なし)
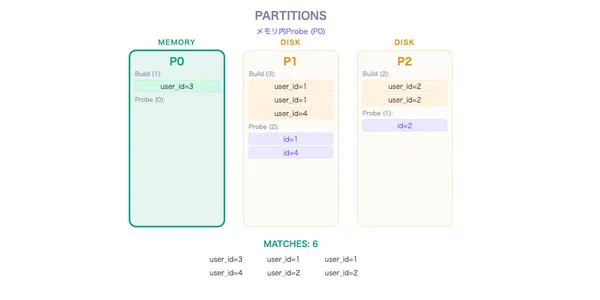
Hybrid Hash Join
Grace Hash Joinの改良版。1パーティションをメモリに保持してI/Oを30-50%削減

ビットマップインデックス(Bitmap Index)
カラム値ごとにビット配列を持ちAND/OR/NOTをビット演算で高速処理するインデックス

コストベース最適化
テーブル統計情報を元に複数の実行プランのコストを比較し最小コストのプランを選択する最適化手法
拡張可能ハッシング(Extendible Hashing)
ディレクトリを倍増させて動的にバケットを拡張するハッシュ方式