ハッシュインデックス(Hash Index)
ハッシュ関数でキーからバケットを直接計算し、平均 O(1) で検索・挿入・削除を実現する静的ハッシュインデックス
📌ハッシュインデックスとは
ハッシュインデックスは、ハッシュ関数を使ってキーからデータの格納位置を直接計算するインデックス構造です。B-Treeがルートから枝を辿って目的のデータにたどり着く「木構造型」の索引であるのに対し、ハッシュインデックスは計算一発で格納場所を特定する「直接アドレッシング型」の索引です。内部的にはバケット(固定容量のスロット配列)を持ち、ハッシュ関数の出力値をバケット番号としてデータを振り分けます。
日常的な例で考えてみましょう。500ページの本から特定の単語を探すとき、B-Treeは「索引のページを開いて、該当する範囲を絞り込んでいく」方法です。一方ハッシュインデックスは、「単語を計算式に入れると即座にページ番号が出てくる」方法です。途中の比較や絞り込みが一切不要で、一発で目的地にたどり着けます。
技術的に見ると、ハッシュ関数は任意の入力を固定範囲の整数値に変換する決定的関数です。「決定的」とは、同じ入力に対して必ず同じ出力を返すこと。最も基本的なハッシュ関数は h(key) = key mod N(Nはバケット数)で、割り算の余りをそのままバケット番号として使います。
- h(42)=42 mod 4 = 2→バケット[2]
- h(17)=17 mod 4 = 1→バケット[1]
- h(8)= 8 mod 4 = 0→バケット[0]
- h(37)=37 mod 4 = 1→バケット[1](キー17と衝突)
この仕組みにより、ハッシュインデックスは平均O(1)(定数時間)で等価検索を実現します。B-Treeの検索がO(log n)であるのに対し、ハッシュインデックスはデータ量に依存しません。1万件でも1億件でも、ハッシュ値を1回計算してバケットにアクセスするだけです。これは配列の添字アクセス array[i] がO(1)であるのと同じ原理で、ハッシュ値がそのまま配列のインデックスになります。
ただし、重要なトレードオフがあります。ハッシュ関数は入力値の大小関係(順序)を保存しません。h(100)=0, h(101)=1, h(102)=2 のように連続する保証はなく、h(104)=0 のように飛びます。このため範囲検索には使えません。
また、複数のキーが同じバケットに割り当てられる「衝突(collision)」が避けられず、衝突が増えると検索性能がO(1)からO(n)に劣化します。そのためバケット数やバケット容量の設計が性能を左右します。
実務では、等価検索が支配的なワークロードで広く採用されています。
- MySQLMEMORYストレージエンジンでインメモリテーブル専用のハッシュインデックスを提供
- PostgreSQLHash Index をサポート。バージョン10以降でWAL(書き込み先行ログ)対応し実用レベルに
- Redis内部データ構造としてハッシュテーブルを採用。全キー検索の基盤
- Memcachedキャッシュルックアップにハッシュテーブルを使用。キーを指定すれば即座にデータを返す
🔧ハッシュインデックスの仕組み
ハッシュインデックスは、ハッシュ関数とバケット配列の2つで構成されます。キーをハッシュ関数に通してバケット番号を得て、そのバケットにデータを格納・検索します。下の図で全体の流れを見てみましょう。
💾実際のデータベースではどんな値がハッシュされる?
上のツールでは簡略化のために整数のキーを直接 mod N していますが、実際のデータベースでハッシュインデックスの対象になるのはテーブルのカラム値です。ユーザーIDのような整数だけでなく、メールアドレスのような文字列、UUIDなどあらゆるデータ型がハッシュの入力になり得ます。
では文字列のような非数値データはどうやってバケット番号に変換するのでしょうか? 答えは2段階のハッシュです。
CREATE INDEX idx_users_email
ON users USING hash (email);
-- このインデックスが効くクエリ
✓ SELECT * FROM users WHERE email = 'tanaka@example.com';
-- このインデックスが効かないクエリ
✗ SELECT * FROM users WHERE email LIKE 'tanaka%';
✅ハッシュインデックスの特徴
- ⚡平均O(1)のランダムアクセス — なぜO(1)なのか? それは配列のインデックスアクセスと同じ原理だからです。array[2] が一瞬で取得できるのと同じように、h(key) の計算結果がそのままバケット番号になり、メモリ上のアドレスが即座に判明します。WHERE id = 42 のような等価検索(=)に最適です。
- 🚫範囲検索に使えない — WHERE price BETWEEN 100 AND 500 のようなクエリには不向きです。なぜなら、h(100) = 0, h(101) = 1, h(102) = 2... というように、ハッシュ値は元の数字の順序を保たないためです。100から200の範囲を取得するには、すべてのバケットを調べる必要があり、ハッシュインデックスの意味がなくなります。
- 📦バケット方式 — バケットとは「郵便局の仕分け棚」のようなものです。手紙の宛先(キー)を見て、対応する棚(バケット)に入れます。h(key) = key mod N でバケット番号を決定し、シンプルな計算で格納先が即座に判明します。
- ⛓️オーバーフローチェーン — 棚が満杯になったら隣に仮の棚を増設するイメージです。バケットが満杯になると、新しいバケットを鎖状に連結して対応します。ただし、チェーンが長くなるほど目的のデータを見つけるのに時間がかかり、最悪の場合O(1)ではなくO(n)に近づきます。
- 📊負荷率が性能の鍵 — 具体的に計算してみましょう。バケット4個 × 容量3 = 最大12個のスロットがあります。8個のキーが入っていれば負荷率は 8/12 ≒ 0.67 です。0.7を超えたら注意、1.0を超えるとオーバーフローが頻発し、性能が大幅に低下します。
🎯ユースケース
📖用語解説
・文字列: hashtext('tanaka@example.com') → 内部整数値 → mod N
・UUID: hashuuid('a3f8-...') → 内部整数値 → mod N
チェーン長3: 比較3回
チェーン長10: 比較10回(かなり遅い)
チェーン長100: 比較100回(ほぼ線形探索と同じ)
Java HashMap: デフォルト閾値0.75(超えると2倍にリサイズ)
Redis: 負荷率1.0を超えると段階的にリハッシュ
🪜ハッシュインデックスの手順
バケット数4、容量3の設定で、キー 5, 12, 42, 37 を順に挿入する例で手順を見ていきましょう。
h(5) = 5 mod 4 = 1 → バケット[1]に挿入
h(12) = 12 mod 4 = 0 → バケット[0]に挿入
h(42) = 42 mod 4 = 2 → バケット[2]に挿入
h(37) = 37 mod 4 = 1 → バケット[1]に挿入(5と衝突)
📊計算量と他の手法との比較
- ✓等価検索(WHERE id = ?)がほとんどの場合 — たとえば「ユーザーIDでプロフィールを取得」のようなクエリが大部分を占めるテーブル
- ✓セッション管理・キャッシュなどキーで1件取得する用途 — セッションIDやAPIキーなどランダム文字列でのルックアップ
- ✓ユニーク制約の重複チェック — メールアドレスやユーザー名の一意性を高速に確認したい場合
- ✓順序やソートが一切不要な場合 — ORDER BY や GROUP BY を使わないことが確実なテーブル
- ✓範囲検索(BETWEEN, >, <)が必要な場合 — 例:WHERE created_at BETWEEN '2024-01-01' AND '2024-12-31'
- ✓ORDER BYでソートされた結果が必要な場合 — 例:ORDER BY price ASC でインデックスの順序をそのまま利用
- ✓LIKE 'prefix%' のような前方一致検索 — 例:WHERE name LIKE '田中%' で「田中」で始まる名前を効率的に検索
- ✓インデックスを使った最小値・最大値の取得 — MIN(price) や MAX(date) をインデックスの端から即座に取得
CREATE INDEX idx_users_email ON users USING hash (email);
関連コンテンツ
拡張可能ハッシング(Extendible Hashing)
ディレクトリを倍増させて動的にバケットを拡張するハッシュ方式
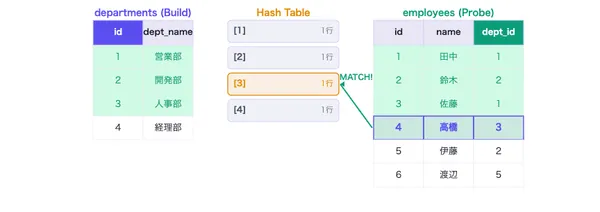
Hash Join
小テーブルからハッシュテーブルを構築し大テーブルでプローブする等価結合アルゴリズム
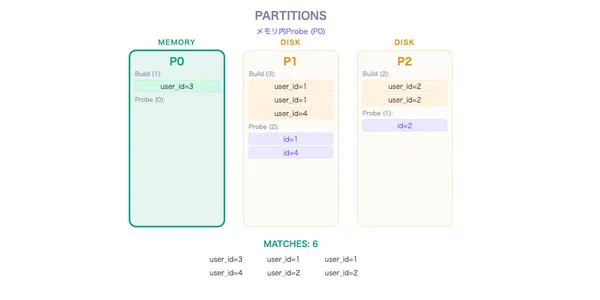
Hybrid Hash Join
Grace Hash Joinの改良版。1パーティションをメモリに保持してI/Oを30-50%削減
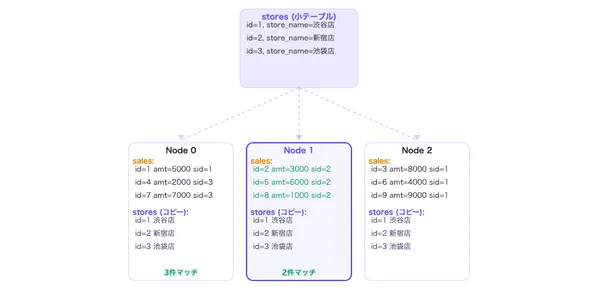
Broadcast Join
分散環境で小テーブルを全ノードにブロードキャストしてローカルJoinする手法
External Merge Sort
メモリに収まらないデータをディスクを使ってソートするアルゴリズム
GiST
B-Treeを一般化した汎用検索木フレームワーク。範囲型・空間データ・全文検索に対応