CLASSIFICATION VISUALIZER
k近傍法(KNN)
「近くにいる仲間の多数決」で分類する――最もシンプルで直感的な分類アルゴリズム
解説
📌k近傍法とは
k近傍法(KNN: k-Nearest Neighbors)は、新しいデータを「最も近いk個のデータ」の多数決で分類するアルゴリズムです。 たとえば引っ越し先の地域を知りたいとき、近所の5軒がすべてファミリー世帯なら「ここはファミリー向けの地域だろう」と判断する。これがKNNの発想です。
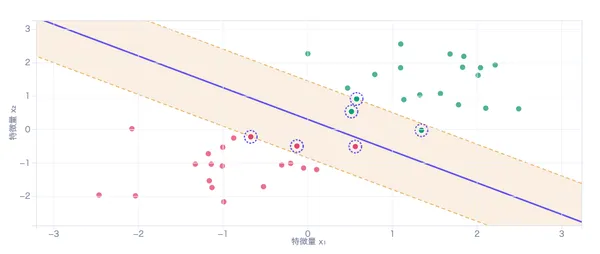
上のグラフで、青い点がクラス0、赤い点がクラス1のデータです。 グラフをクリックすると黄色のクエリ点が配置され、そこから最も近いk個の点(緑の破線リング)が選ばれます。 そのk個の中でどちらのクラスが多いかで、クエリ点のクラスが決まります。
背景の色の濃淡は、その位置でKNNが予測するクラスと信頼度を示しています。これが決定境界です。 kの値や距離指標を変えると、この決定境界がどう変化するか観察してみてください。
📌KNNの特徴
- 📦怠惰学習(Lazy Learning):訓練フェーズで何も学習しません。データをそのまま記憶しておき、予測時に初めて距離を計算します。SVM や決定木のように事前にモデルを構築するアルゴリズムとは対照的です。
- 🎯非線形な決定境界:直線では分けられない複雑な形のデータでも、データの分布に沿った境界を自然に作れます。上のツールで「月型」データに切り替えると、KNNが曲線的な境界を作る様子を確認できます。
- 🔢kの値で複雑さが変わる:k=1だと最も近い1点だけで決めるので境界がギザギザに、k=15のように大きくすると滑らかになります。上のスライダーでkを変えて決定境界の変化を観察してみてください。
- 📐距離指標の選択:ユークリッド距離(直線距離)が一般的ですが、マンハッタン距離(碁盤目距離)なども使えます。データの性質に合った距離指標を選ぶことが重要です。
- ⚠️次元の呪い:特徴量の次元が増えると、すべての点が互いに遠くなり「近い」の意味が薄れます。高次元データでは次元削減(PCAなど)と組み合わせるのが一般的です。
- 🐌予測が遅い:予測のたびに全データとの距離を計算するため、データが大きいと遅くなります。10万件程度ならkd-treeなどの高速化手法で対応できますが、数百万件を超えると他の手法が有利です。
📌ユースケース
🎬 レコメンドシステム
Netflix や Amazon のおすすめ機能。視聴履歴や購買パターンが似たユーザー(近傍)の評価を参考に、あなたが好みそうなコンテンツを推薦します。
✍️ 手書き数字認識
USPSやMNISTの手書き文字分類。各画像をピクセルベクトルにして、最も似た既知の数字画像と照合します。scikit-learnのチュートリアルでも定番の例題です。
🏥 医療診断の補助
患者の検査値(血圧、血糖値など)が似ている過去の症例を検索し、病気のリスクを推定。解釈のしやすさが医療分野で評価されています。
💳 不正検知
クレジットカードの不正利用検知。取引のパターン(金額、時間帯、場所)が過去の正常な取引と大きく異なるかどうかで異常を判定します。
📌用語解説
k(近傍数)
= 多数決に参加する「近所の仲間」の人数
= 多数決に参加する「近所の仲間」の人数
予測するときに参照する最も近いデータ点の数です。 k=1なら一番近い1人の意見だけで決め、k=5なら近い5人の多数決で決めます。kが小さい:境界が複雑になり、ノイズに敏感(過学習しやすい)。kが大きい:境界が滑らかになり安定するが、境界付近の精度が下がることも。上のツールでkを1→3→7→15と変えると、決定境界がどんどん滑らかになるのが分かります。奇数を使うと同数票にならないので一般的です。
ユークリッド距離(Euclidean Distance)
= 2点間の「直線」距離
= 2点間の「直線」距離
定規で測った直線距離です。最も直感的で、KNNのデフォルトの距離指標として広く使われます。数式: d = √((x₁−x₂)² + (y₁−y₂)²)具体例: 点A(1,2)と点B(4,6)の距離 = √((4-1)²+(6-2)²) = √(9+16) = √25 = 5.0
マンハッタン距離(Manhattan Distance)
= 碁盤の目に沿った「迂回」距離
= 碁盤の目に沿った「迂回」距離
名前はニューヨークのマンハッタンの碁盤目状の街路に由来します。 斜めに横切れず、水平・垂直方向にのみ移動した場合の距離です。 格子状に配置されたデータや、各特徴量のスケールが異なるデータで有効です。数式: d = |x₁−x₂| + |y₁−y₂|具体例: 点A(1,2)と点B(4,6)の距離 = |4-1|+|6-2| = 3+4 = 7.0(ユークリッドの5.0より大きい)
多数決(Majority Vote)
= k個の近傍のラベルで最も多いクラスを選ぶ
= k個の近傍のラベルで最も多いクラスを選ぶ
KNNの予測方法です。k個の近傍点のうち、最も多いクラスのラベルを予測結果とします。 信頼度は「多数派の割合」で表し、全員一致なら100%、ギリギリの多数決なら50%台になります。同数票を避けるため、kには奇数を選ぶのが一般的です。同数の場合は距離が近い方を優先する方法もあります。具体例: k=5 で近傍が [クラス1, クラス0, クラス1, クラス1, クラス0] なら、クラス1が3票で多数 → 予測はクラス1(信頼度60%)
決定境界(Decision Boundary)
= 予測クラスが切り替わる「境界線」
= 予測クラスが切り替わる「境界線」
空間の各点について多数決の結果が変わる境界線です。 KNNの決定境界はデータ点の配置から自然に決まるため、直線とは限らず複雑な曲線になることがあります。 グラフの背景色(青と赤の淡い色)がこれを表しています。kが小さいとギザギザな境界(過学習の兆候)、kが大きいと滑らかな境界(汎化重視)になります。
Leave-One-Out交差検証(LOO-CV)
= 1個ずつ抜いて評価する方法
= 1個ずつ抜いて評価する方法
データを1つずつ取り出し、残りの全データで分類して正解率を測る評価方法です。 上のツールの「正解率(LOO)」は、各点を1つずつ除外して残りで分類し、自分自身のクラスと一致するかを確認した結果です。小さなデータセットで偏りの少ない評価ができますが、データ数が多いと計算量が大きくなります。
📌KNNの分類手順
1
データを用意する
既にクラスが分かっているデータを集めます。KNNでは事前に学習(モデル構築)を行わず、データをそのまま保存しておくだけです。
2
新しい点との距離を全データで計算
分類したい新しい点が来たら、すべての訓練データとの距離を計算します。
3
距離が近い順にk個を選ぶ
距離を昇順にソートし、上位k個を取り出します。この点が「近傍」です。
4
多数決で分類を決定
k個の近傍のクラスラベルを集計し、最も多いクラスを予測結果とします。
📌kの選び方と他の手法との比較
kの選び方はKNNで最も重要な判断です。k=1は最も近い1点だけで判断するため、データのノイズに振り回されやすい(過学習)。 一方、kが大きすぎると遠くの無関係な点まで参照してしまい、境界がぼやけて分類の精度が下がります。
k = 1
境界が複雑すぎる。ノイズに敏感で過学習しやすい
k = √n
経験則としてデータ数の平方根が目安。バランスが良い
k = n
全データで多数決。常に多数派クラスを返すだけになり、分類の意味がなくなる
実用上は交差検証(Cross-Validation)で複数のkを試し、精度が最も高いkを選びます。 上のツールでkを変えながら正解率(LOO)の変化を確認してみてください。
他の分類手法との比較
| 手法 | 訓練速度 | 予測速度 | 境界の形 | 解釈しやすさ |
|---|---|---|---|---|
| KNN | 不要 | 遅い | 非線形 | 高い |
| ロジスティック回帰 | 速い | 速い | 線形 | 高い |
| SVM | 普通 | 速い | 線形/非線形 | 中程度 |
| 決定木 | 速い | 速い | 軸平行 | 非常に高い |
| ランダムフォレスト | 普通 | 普通 | 非線形 | 低い |
📌次元の呪い(Curse of Dimensionality)
次元の呪いとは、特徴量の次元が増えるにつれて、距離ベースのアルゴリズムの性能が急激に劣化する現象です。 KNNは「近い点」を探すアルゴリズムなので、この問題の影響を最も受けやすい手法の一つです。
なぜ次元が増えると「近い」の意味が薄れるのか
1
空間の体積が指数的に膨張する
1次元で0〜1の区間にデータが10個あると、平均0.1間隔で点が並びます。 しかし2次元(正方形)では同じ10個が面積1.0の中にバラバラに散らばり、 3次元(立方体)ではさらにスカスカになります。同じ密度を保つには指数的にデータ数を増やす必要があります。
2
全ての点が「遠く」なる
高次元空間では、最も近い点と最も遠い点の距離の差が相対的に小さくなります。 全員がほぼ等距離にいるなら、「近い順にk個選ぶ」という操作に意味がなくなります。
3
無関係な特徴量がノイズになる
100個の特徴量のうち、分類に本当に役立つのが3個だけなら、残り97個は距離の計算にノイズを加えるだけです。
対策
- 📉次元削減(PCA):主成分分析(PCA)で特徴量を数個〜数十個に圧縮してからKNNを適用します。
- 🎯特徴選択:分類に本当に役立つ特徴量だけを選び、無関係なものを除外します。
- 📏距離の重み付け:重要な次元に大きな重みを付けて距離を計算します。
- 🔄標準化・正規化:特徴量のスケールを揃えることで、距離計算のバランスを保ちます。