📌
最尤推定法とは最尤推定法(MLE: Maximum Likelihood Estimation)は、手元のデータから「平均」と「ばらつき」を求める手法です。
たとえば、30人のテストの点数データがあるとします。このデータを眺めると「だいたい平均65点くらいで、ばらつきは12点くらいかな」と感覚的にわかります。 でも「だいたい」ではなく数学的に最も正確な平均とばらつきの値を求めたい。そのための方法がMLEです。
求め方がユニークです。「平均=60、ばらつき=10」「平均=65、ばらつき=12」…と候補を片っ端から試して、どの組み合わせが今のデータに一番フィットするかを数学的に比較し、最もフィットするものを答えとします。 1922年にR.A.フィッシャーが体系化し、統計学・機械学習で最も広く使われている推定手法です。
💡
たとえ話で理解する:「どの袋から引いた?」点数が書かれたボールがたくさん入った袋が3つあります。
あなたはどの袋から引いたか知らされずに、30個のボールを引きました。結果は 42, 48, 55, … , 85, 92 点でした。
さて、あなたはどの袋から引いた可能性が一番高いですか?
- 袋A(平均60点)→ 92点のボールが出るのは珍しい。ちょっと考えにくい。
- 袋C(平均70点)→ 42点のボールが出るのは珍しい。これも考えにくい。
- 袋B(平均65点)→ 42点も92点もそこそこ出る。一番ありそう!
この「どの袋から引いたのが一番ありそうか?」を数学的に計算するのがMLEです。 「袋Bから引いた可能性が一番高い」というときの「可能性の高さ」を尤度(ゆうど)と呼びます。 MLEは袋を3つだけでなく、無限の候補(平均60.0, 60.1, 60.2, …)すべてを比較して、尤度が最大になる袋を見つけます。
🛠️
「袋えらび」を上のツールで体験してみよう- ① 袋を選ぶ体験:μ のスライダーは「どの袋から引いたか?」の候補を手動で切り替えるものです。 スライダーを動かすとピンクの破線(あなたが選んだ袋の分布)が左右に動きます。ヒストグラム(実際に引いたボール)と曲線がずれるほど「この袋じゃなさそう」= 尤度が低い状態です。
- ② 袋の広さを変える体験:σ のスライダーは「袋の中のボールがどれくらいばらついているか」を調整します。 σ を大きくすると平たく広がり、小さくすると鋭いピークになります。
- ③ MLEの答え合わせ:緑の実線がMLEの答え(尤度が最大になる袋)です。 スライダーをどう動かしても、右下の「対数尤度(手動)」は「対数尤度(MLE)」を超えられないことを確認してみてください。
- ④ 対数尤度グラフ:ツール下部のグラフは「μ(またはσ)を変えたときに尤度がどう変わるか」を描いたものです。緑の点が頂上 = MLEの推定値です。
⚡
最尤推定法の特徴- 🎯パラメータ推定の汎用手法:正規分布に限らず、ポアソン分布・指数分布・ロジスティック回帰など、確率モデルであれば何にでも適用できます。「この分布でデータが出る確率を最大にするパラメータは何か?」という問いに統一的に答える万能ツールです。
- 📊一致性と漸近正規性:データが増えるほど推定値が真の値に近づく(一致性)、かつ推定値の分布が正規分布に近づく(漸近正規性)という理論的な保証があります。つまりデータを増やせば必ず精度が上がるという安心感があります。
- ⚡正規分布なら公式一発:正規分布の場合、MLEの答えは μ̂ = データの平均、σ̂ = データの標準偏差と明快です。上のツールでスライダーを動かした瞬間に結果が変わるのはこのためです。ただし複雑なモデルでは反復的な最適化(勾配降下法など)が必要になります。
- 🔗最小二乗法との関係:「誤差が正規分布に従う」と仮定すると、最尤推定は最小二乗法と完全に一致します。つまり最小二乗法は「正規分布を仮定したときのMLE」という特殊ケースです。MLEのほうが一般的な枠組みなので、正規分布以外のモデルにも対応できます。
- ⚠️データが少ないと不安定:MLEはデータだけから推定するので、データが少ないと推定値がブレやすくなります。上のツールでサンプル数を30→5に減らすと、毎回大きく結果が変わるのがわかります。データが少ない場合はベイズ推定(事前知識を加える方法)のほうが安定します。
🏢
最尤推定法のユースケース🤖 ロジスティック回帰
scikit-learn や TensorFlow の分類モデル。「スパムか否か」「病気か否か」の判定で、パラメータ学習にMLEを使っています
🗣️ 自然言語処理
ChatGPTなどの言語モデルの学習。「次に来る単語の確率」を最大化する学習が、まさに最尤推定です
📈 生存時間分析
医療データで「薬を飲んでから何日で回復するか」のモデル。ワイブル分布などのパラメータをMLEで推定します
🏭 品質管理
工場の不良品率や機械の故障率の推定。ポアソン分布や指数分布のパラメータをMLEで求め、異常検知に活用します
📖
用語解説尤度(Likelihood)
= 「このパラメータのとき、データが出る確率」
パラメータ θ を決めたとき、手元のデータ x₁, x₂, …, xₙ がどれだけ「ありそうか」を測る数値です。 各データ点の確率密度の積 L(θ) = f(x₁;θ) × f(x₂;θ) × … × f(xₙ;θ) で計算します。 上のツールでオレンジの縦線が各データ点の尤度を表しています。
例: μ=65, σ=12 のとき、点数70の尤度 = f(70; 65, 12) ≈ 0.030
対数尤度(Log-Likelihood)
= 尤度の対数をとったもの
尤度は非常に小さい数の積になるので、コンピュータでは桁落ちが起きます。 そこで対数をとって ℓ(θ) = ln L(θ) = Σ ln f(xᵢ;θ) と積→和に変換します。 ツール下部の紫色の曲線がこの対数尤度関数です。頂点がMLE推定値に対応します。
対数尤度(MLE)と 対数尤度(手動)
= ツール右上に表示される2つの数値
どちらも「このμとσの組み合わせで、今のデータが出る確率はどれくらいか」を測る数値です。大きい(0に近い)ほど良い推定です。対数尤度(MLE)は、MLEが自動で見つけた最適なμとσでの値です。これが理論上の最大値になります。対数尤度(手動)は、あなたがスライダーで設定したμとσでの値です。スライダーを動かすとリアルタイムに変わります。値がマイナスになるのは正常です。確率は0〜1の小さい数なので、logを取ると必ずマイナスになります。 データが30個あれば、30個分の確率のlogの合計なので -100 や -120 のような大きなマイナスは普通です。絶対値ではなく、2つの値の差に注目してください。手動の値がMLEに近づくほど、良い推定ができている証拠です。
確率密度関数(PDF)
= 「各値がどれくらい出やすいか」を表す曲線
確率密度は確率そのものではありません。テストの点数のような連続データでは「ちょうど65.0点になる確率」は理論上ゼロです。 代わりに「65点付近にどれくらい出やすいか」を高さで表すのが確率密度です。曲線が高いところ → その付近の値がよく出る。低いところ → めったに出ない。 ある区間の面積が、その区間に値が入る確率になります(例:60〜70点の面積 = 60〜70点になる確率)。曲線の下の全体の面積は常に1(= 100%)です。グラフの緑の実線(MLE)とピンクの破線(手動)が正規分布のPDFです。 ヒストグラムの高さも確率密度に変換してあるので、緑の曲線とヒストグラムの高さが揃っているほど「フィットが良い」と読み取れます。
平均 μ(ミュー / Mean)
= 分布の中心位置
正規分布の山のてっぺんの位置です。ツールの「平均 μ」スライダーで変化を確認できます。 MLEの推定値は μ̂ = (1/n) Σxᵢ、つまりデータの単純な平均値です。
例: データ [60, 65, 70] → μ̂ = (60+65+70)/3 = 65
標準偏差 σ(シグマ / Std Dev)
= 分布の広がり具合
σ が大きいと分布が平たく広がり、小さいと鋭いピークになります。ツールの「標準偏差 σ」スライダーで確認できます。 MLEの推定値は σ̂ = √((1/n) Σ(xᵢ − μ̂)²) です。不偏推定量(n−1で割る)とは少し違いますが、データが多ければほぼ同じです。
正規分布(Normal Distribution)
= 自然界で最もよく現れる「釣鐘型」の分布
テストの点数・身長・測定誤差など、多くの現象が正規分布に従います。 2つのパラメータ μ(中心)と σ(広がり)だけで形が決まるシンプルな分布です。 式: f(x; μ, σ) = (1/σ√(2π)) exp(−(x−μ)²/(2σ²))
🪜
最尤推定の手順20人のテストの点数データから、最尤推定で正規分布のパラメータ(μ, σ)を求める流れを見ていきましょう。
1
データを集める
20人のテストの点数を観測します。例:42, 55, 60, 65, 65, 68, 70, 73, 78, 85, …
このデータが「ある正規分布 N(μ, σ²)」から出てきたと仮定します。
2
尤度関数を立てる
「各データ点が出る確率密度」を全部掛け合わせたものが尤度です。正規分布の場合:
L(μ, σ) = Π f(xᵢ; μ, σ)
= Π (1/σ√(2π)) exp(−(xᵢ−μ)²/(2σ²))
20個の確率密度を掛け合わせるので、とても小さい数になります。そこで対数をとって和に変換します:
ℓ(μ, σ) = −(n/2)ln(2π) − n·ln(σ) − Σ(xᵢ−μ)²/(2σ²)
3
微分して最大値を求める
対数尤度を μ と σ でそれぞれ微分して = 0 とおくと、解析的に最適解が求まります:
∂ℓ/∂μ = 0 → μ̂ = (1/n) Σxᵢ
∂ℓ/∂σ = 0 → σ̂ = √((1/n) Σ(xᵢ − μ̂)²)
つまり μ̂ はデータの平均、σ̂ はデータの標準偏差(n で割る版)です。 ツール下部の対数尤度グラフの頂点がまさにこの値に対応します。
4
推定結果を読む
20人の点数データに対して計算すると:
μ̂ ≈ 66.5(平均点)、σ̂ ≈ 12.3(ばらつき)
つまり「このクラスのテストの点数は、平均66.5点、標準偏差12.3点の正規分布から出てきた」と推定されました。 新しい生徒が入ってきたら、66.5 ± 12.3 × 2 ≈ 42〜91 の範囲に約95%の確率で収まると予測できます。
🎯
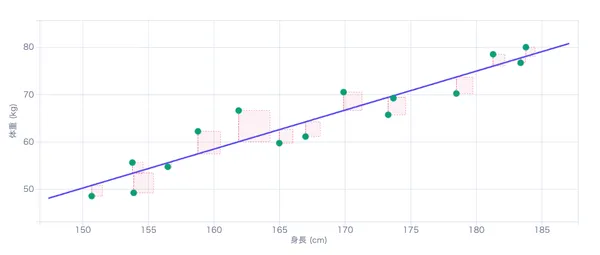
具体例で理解する:クラスのテスト結果を分析あるクラス20人のテスト結果(42, 48, 52, 55, 58, 60, 62, 63, 65, 65, 67, 68, 70, 72, 73, 75, 78, 80, 85, 92点)があります。 このデータから「テストの点数はどんな正規分布に従うか?」を最尤推定で求めましょう。
グラフの読み方
- 緑の実線がMLEで推定した正規分布の曲線(PDF)。ヒストグラムの形に最もフィットする曲線です。
- 紫のヒストグラムが実際のデータ。各ビンの高さは「確率密度」に変換されているので、緑の曲線と直接比較できます。
- x軸上の紫の点が個々のデータ(20人の点数)。点が密集しているところにヒストグラムの山ができています。
この例のMLE推定結果
手順で説明した公式に20人のデータを代入すると:
①平均 μ̂ を求める:全員の点数を足して20で割る。
μ̂ = (42+48+...+92) / 20 = 66.5
②標準偏差 σ̂ を求める:各人の「平均からのずれ²」を平均してルートをとる。
σ̂ = √(Σ(xᵢ − 66.5)² / 20) = 12.0
③対数尤度 を確認:このパラメータでの対数尤度が最大値。
ℓ(66.5, 12.0) = -78.2
結果:このクラスのテストは N(66.5, 12.0²) に従うと推定されました。 つまり平均67点を中心に、±12点くらいのばらつきがある分布です。
ポイント正規分布の場合、MLEの μ̂ はデータの平均値そのものです。これは直感的にも納得できます — データの中心に山を置くのが一番「尤もらしい」からです。 σ̂ も同様に、データのばらつきに合わせた幅が最も尤もらしい。 上のツールでスライダーを動かして、μ や σ をずらすと対数尤度が下がることを確認してみてください。
🔗
最尤推定と最小二乗法はなぜ同じ結果になるのか?回帰モデル y = f(x) + ε で「誤差 ε が正規分布 N(0, σ²) に従う」と仮定すると、尤度を最大にすることと残差の二乗和を最小にすることは数学的に同じになります。
①誤差 εᵢ = yᵢ − f(xᵢ) が N(0, σ²) に従うとき、各データ点の尤度は:
f(yᵢ | xᵢ) = (1/σ√(2π)) exp(−(yᵢ − f(xᵢ))² / (2σ²))
②対数尤度をとると:
ℓ = 定数 − (1/2σ²) Σ(yᵢ − f(xᵢ))²
σ² は定数なので、
ℓ を最大にする = Σ(yᵢ − f(xᵢ))² を最小にする ③Σ(yᵢ − f(xᵢ))² は残差平方和(RSS)そのもの。つまり「誤差が正規分布」という仮定のもとでは、MLE = OLS。最小二乗法は「正規分布を仮定したMLE」の特殊ケースなのです。
MLEの強み誤差が正規分布でないとき(例:外れ値が多い、0以上のデータしかない等)、最小二乗法は不適切になります。 しかしMLEなら、ポアソン分布・指数分布・ラプラス分布など、データの性質に合った分布を選んでパラメータを推定できます。 これが「MLEは最小二乗法の一般化」と言われる理由です。
⚖️
MLE vs ベイズ推定MLEは「データだけで推定する」手法です。一方、ベイズ推定は「事前知識 + データ」で推定します。どちらが良いかはケースバイケースです。
出力
1つの推定値(点推定)
分布全体(不確実性も分かる)
データが少ないとき
不安定になりやすい
事前知識で安定
実は、ベイズ推定で事前分布を「何も知らない」状態(一様分布)にすると、MAP推定(事後分布の最頻値)はMLEと一致します。MLEは「事前知識なしのベイズ推定」とも解釈できます。